


As an Amazon Associate I earn from qualifying purchases.

Avoid to content
Calculate expenses scale with the square of the input size. That’s not terrific.
Credit: Aurich Lawson|Getty Images
Big language designs represent text utilizing tokens, each of which is a couple of characters. Brief words are represented by a single token (like “the” or “it”whereas bigger words might be represented by numerous tokens (GPT-4o represents “indivisible” with “ind,” “iv,” and “isible”.
When OpenAI launched ChatGPT 2 years back, it had a memory– called a context window– of simply 8,192 tokens. That exercises to approximately 6,000 words of text. This indicated that if you fed it more than about 15 pages of text, it would “forget” info from the start of its context. This restricted the size and intricacy of jobs ChatGPT might deal with.
Today’s LLMs are even more capable:
- OpenAI’s GPT-4o can manage 128,000 tokens (about 200 pages of text).
- Anthropic’s Claude 3.5 Sonnet can accept 200,000 tokens (about 300 pages of text).
- Google’s Gemini 1.5 Pro enables 2 million tokens (about 2,000 pages of text).
Still, it’s going to take a lot more development if we desire AI systems with human-level cognitive capabilities.
Many individuals imagine a future where AI systems have the ability to do numerous– possibly most– of the tasks carried out by people. Numerous human employees check out and hear hundreds of millions of words throughout our working years– and we take in even more info from sights, sounds, and smells in the world around us. To attain human-level intelligence, AI systems will require the capability to take in comparable amounts of info.
Now the most popular method to develop an LLM-based system to deal with big quantities of details is called retrieval-augmented generation (RAG). These systems look for files pertinent to a user’s inquiry and after that place the most pertinent files into an LLM’s context window.
This often works much better than a standard online search engine, however today’s RAG systems leave a lot to be preferred. They just produce excellent outcomes if the system puts the most appropriate files into the LLM’s context. The system utilized to discover those files– frequently, browsing in a vector database– is not really advanced. If the user asks a complex or complicated concern, there’s a great chance the RAG system will obtain the incorrect files and the chatbot will return the incorrect response.
And RAG does not make it possible for an LLM to factor in more advanced methods over great deals of files:
- A legal representative may desire an AI system to evaluate and sum up numerous countless e-mails.
- An engineer may desire an AI system to examine countless hours of cam video from a factory flooring.
- A medical scientist may desire an AI system to recognize patterns in 10s of countless client records.
Each of these jobs might quickly need more than 2 million tokens of context. We’re not going to desire our AI systems to begin with a tidy slate after doing one of these tasks. We will desire them to acquire experience with time, similar to human employees do.
Superhuman memory and endurance have actually long been essential selling points for computer systems. We’re not going to wish to provide up in the AI age. Today’s LLMs are clearly subhuman in their capability to soak up and comprehend big amounts of details.
It’s real, obviously, that LLMs take in superhuman amounts of details at training time. The current AI designs have actually been trained on trillions of tokens– even more than any human will check out or hear. A lot of important details is exclusive, time-sensitive, or otherwise not readily available for training.
We’re going to desire AI designs to check out and keep in mind far more than 2 million tokens at reasoning time. Which will not be simple.
The crucial development behind transformer-based LLMs is attention, a mathematical operation that permits a design to “think of” previous tokens. (Check out our LLM explainer if you desire an in-depth description of how this works.) Before an LLM creates a brand-new token, it carries out an attention operation that compares the current token to every previous token. This suggests that standard LLMs get less and less effective as the context grows.
Great deals of individuals are dealing with methods to resolve this issue– I’ll talk about a few of them later on in this post. Initially I must discuss how we ended up with such an unwieldy architecture.
The “brains” of computers are main processing systems (CPUs). Generally, chipmakers made CPUs quicker by increasing the frequency of the clock that serves as its heart beat. In the early 2000s, overheating forced chipmakers to primarily desert this method.
Chipmakers began making CPUs that might carry out more than one guideline at a time. They were held back by a programs paradigm that needs directions to mainly be carried out in order.
A brand-new architecture was required to maximize Moore’s Law. Go into Nvidia.
In 1999, Nvidia began offering graphics processing systems (GPUs) to accelerate the making of three-dimensional video games like Quake III ArenaThe task of these PC add-on cards was to quickly draw countless triangles that comprised walls, weapons, beasts, and other items in a video game.
This isnota consecutive programs job: triangles in various locations of the screen can be attracted any order. Rather than having a single processor that performed guidelines one at a time, Nvidia’s very first GPU had actually a lots specialized cores– efficiently small CPUs– that worked in parallel to paint a scene.
Gradually, Moore’s Law made it possible for Nvidia to make GPUs with 10s, hundreds, and ultimately countless calculating cores. Individuals began to understand that the enormous parallel computing power of GPUs might be utilized for applications unassociated to computer game.
In 2012, 3 University of Toronto computer system researchers– Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton– utilized a set of Nvidia GTX 580 GPUs to train a neural network for acknowledging images. The huge computing power of those GPUs, which had 512 cores each, enabled them to train a network with a then-impressive 60 million specifications. They went into ImageNet, a scholastic competitors to categorize images into among 1,000 classifications, and set a brand-new record for precision in image acknowledgment.
Soon, scientists were using comparable strategies to a variety of domains, consisting of natural language.
RNNs worked relatively well on brief sentences, however they fought with longer ones– to state absolutely nothing of paragraphs or longer passages. When thinking about a long sentence, an RNN would in some cases “forget” an essential word early in the sentence. In 2014, computer system researchers Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio found they might enhance the efficiency of a frequent neural network by including an attention system that permitted the network to “recall” at earlier words in a sentence.
In 2017, Google released ” Attention Is All You Need,” among the most essential documents in the history of artificial intelligence. Structure on the work of Bahdanau and his associates, Google scientists ignored the RNN and its concealed states. Rather, Google’s design utilized an attention system to scan previous words for appropriate context.
This brand-new architecture, which Google called the transformer, showed extremely substantial due to the fact that it got rid of a severe traffic jam to scaling language designs.
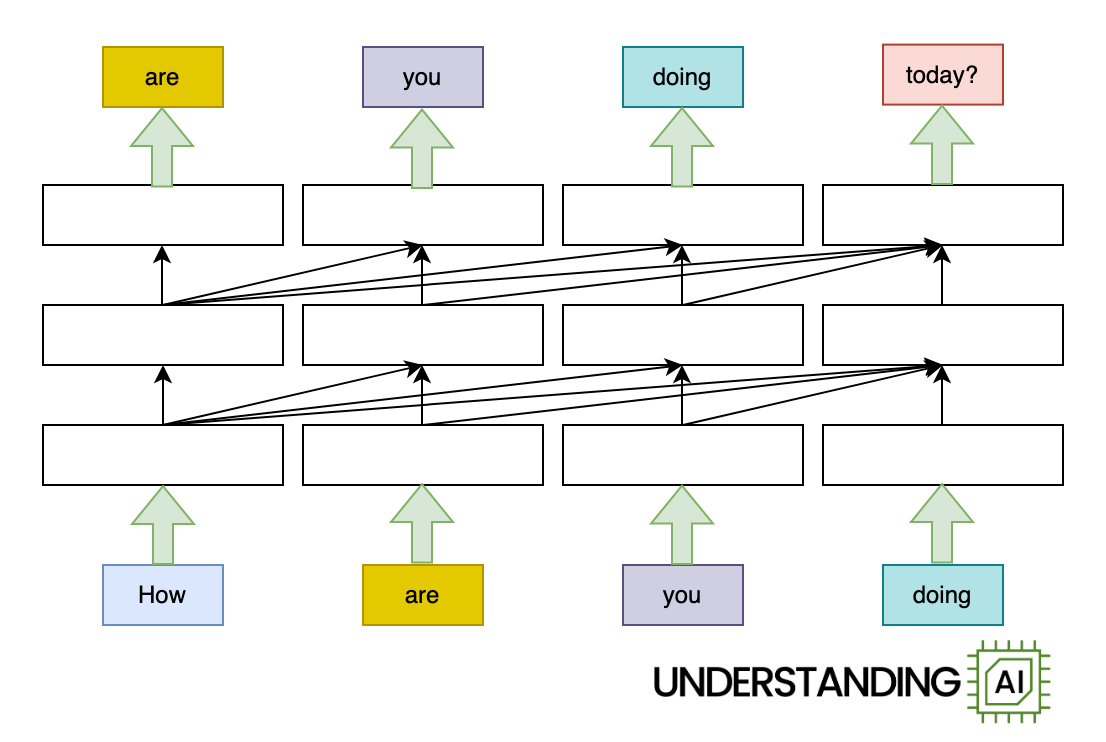
Here’s an animation highlighting why RNNs didn’t scale well:
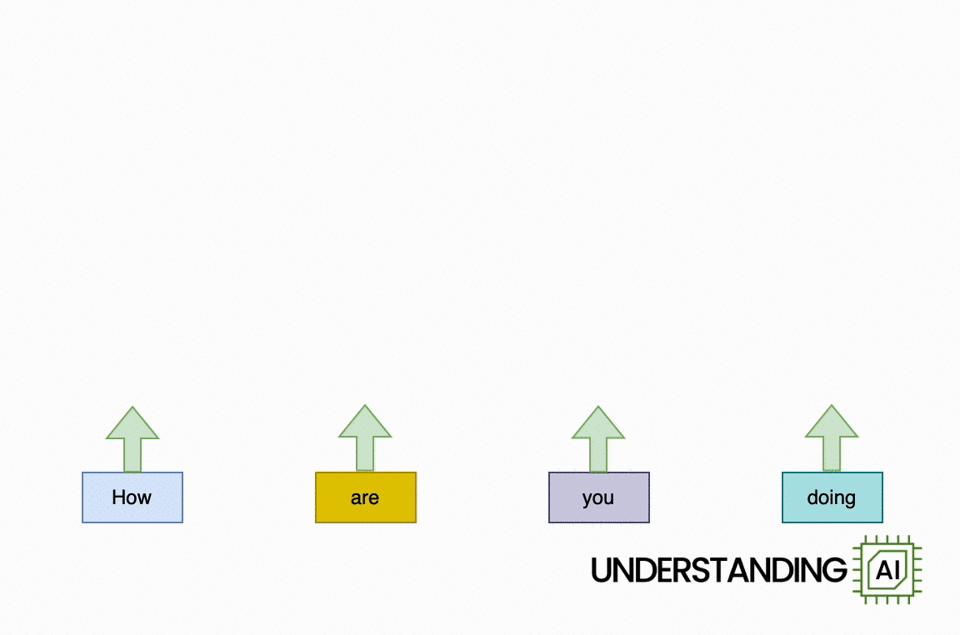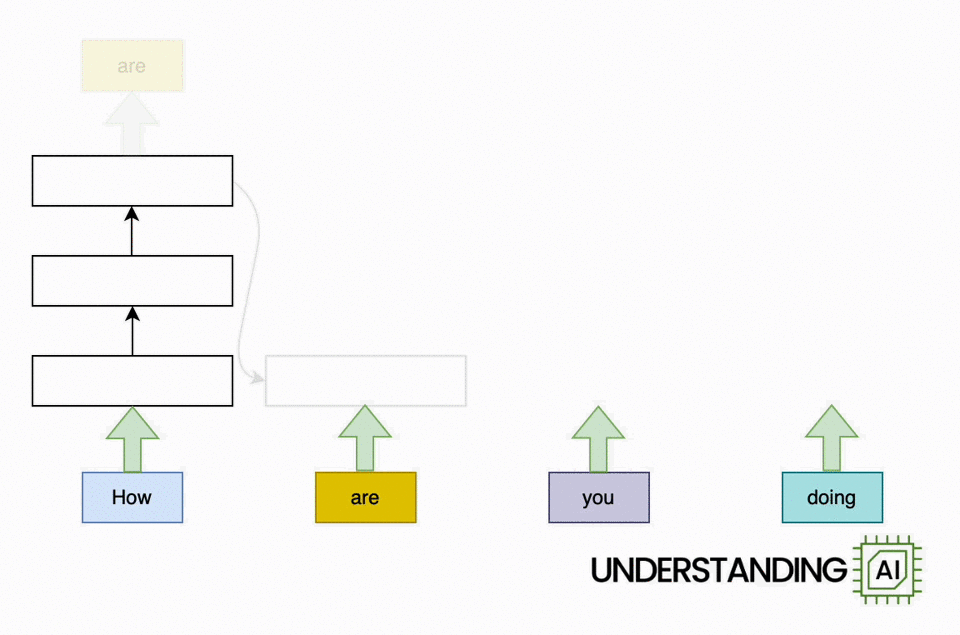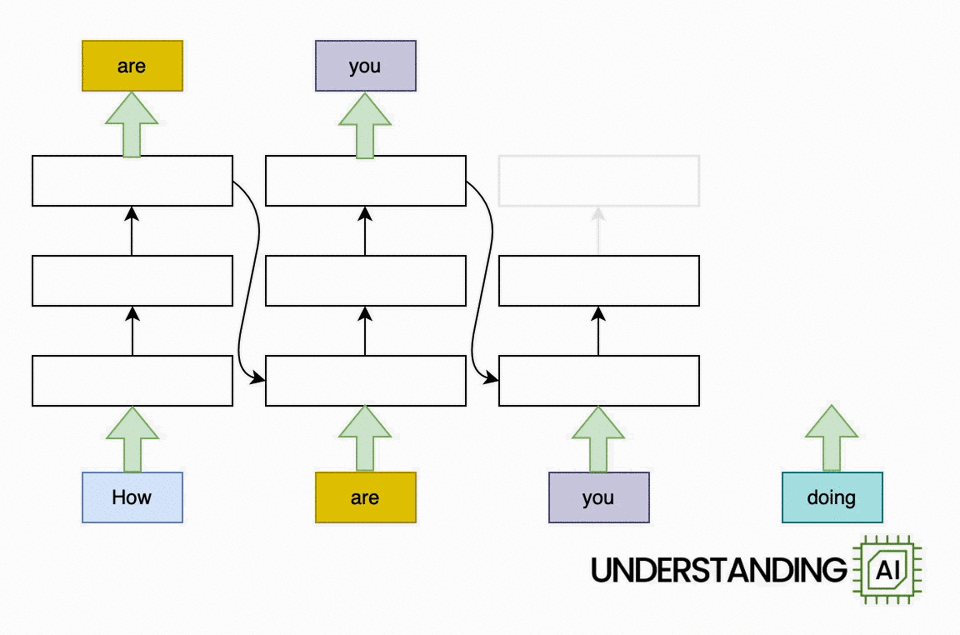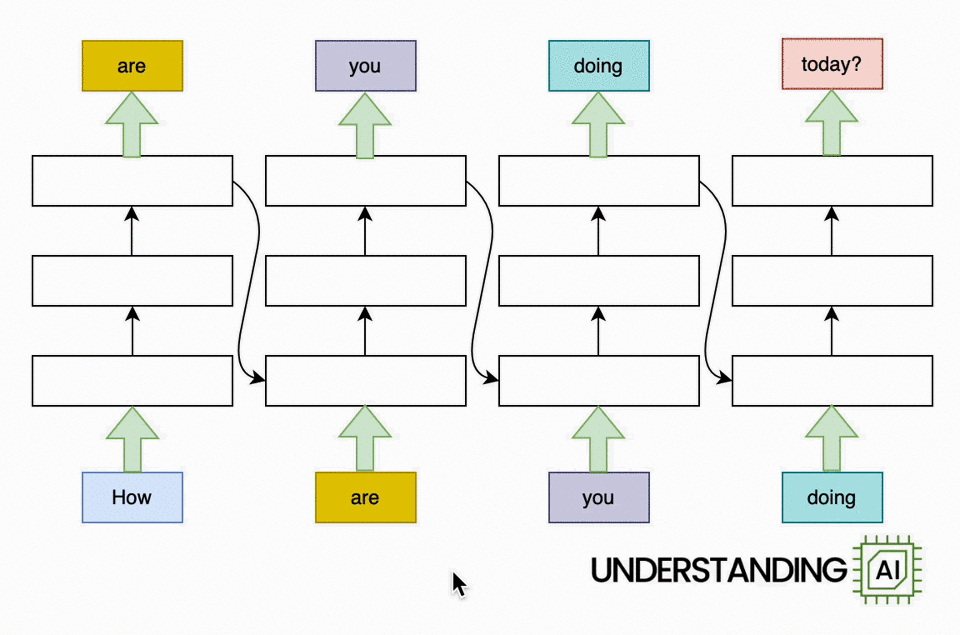
This theoretical RNN attempts to anticipate the next word in a sentence, with the forecast displayed in the leading row of the diagram. This network has 3 layers, each represented by a rectangular shape. It is naturally direct: it needs to finish its analysis of the very first word,” How,” before passing the surprise state back down layer so the network can begin to examine the 2nd word,” are.”
This restriction wasn’t a huge offer when artificial intelligence algorithms operated on CPUs. When individuals began leveraging the parallel computing power of GPUs, the direct architecture of RNNs ended up being a major challenge.
The transformer eliminated this traffic jam by permitting the network to “think of” all the words in its input at the exact same time:
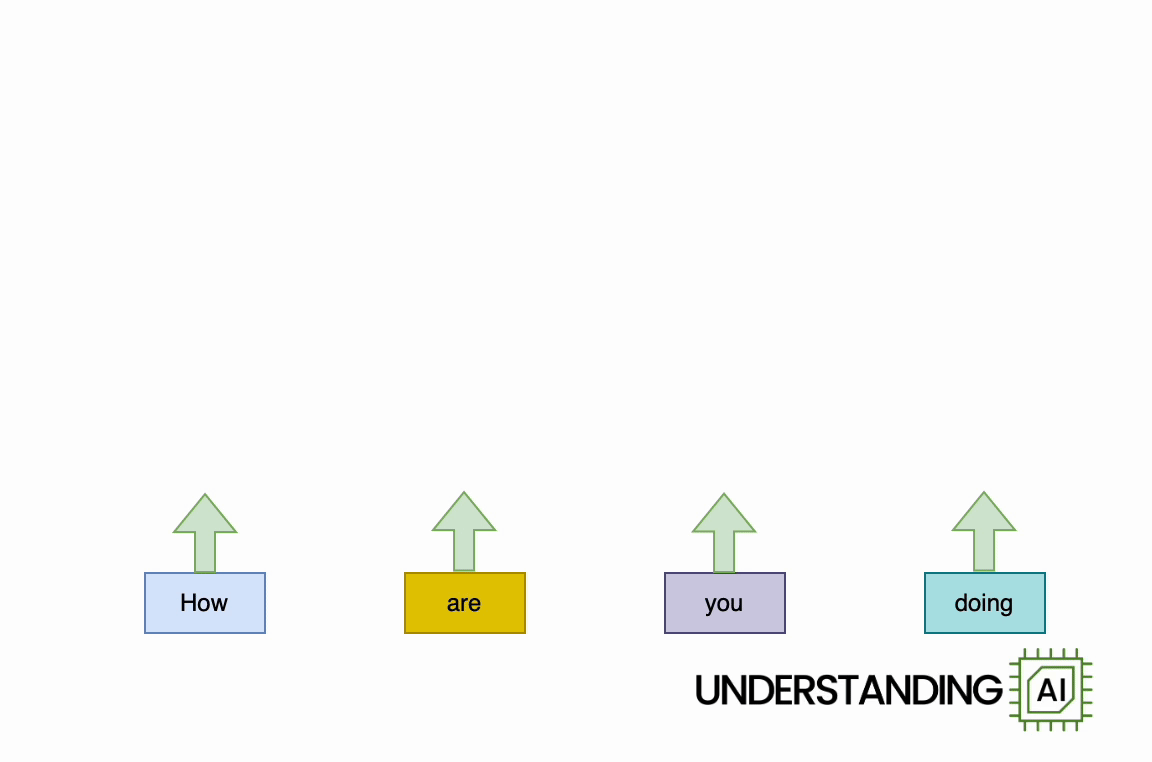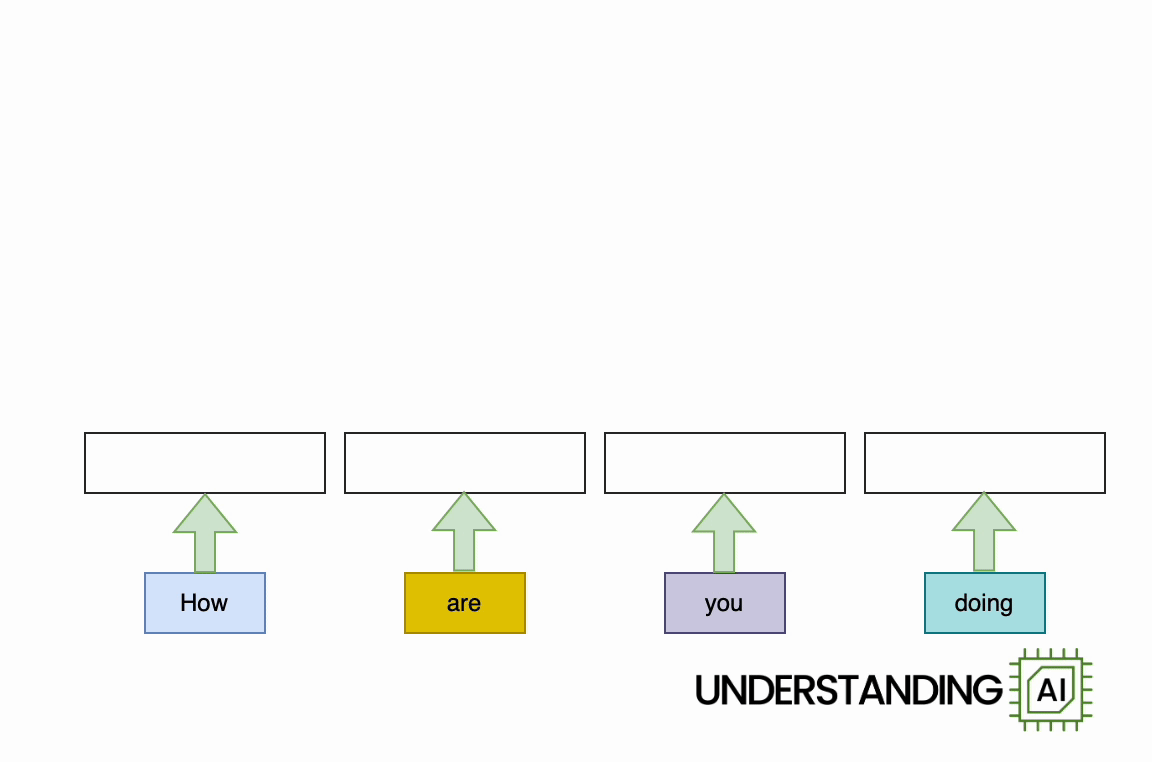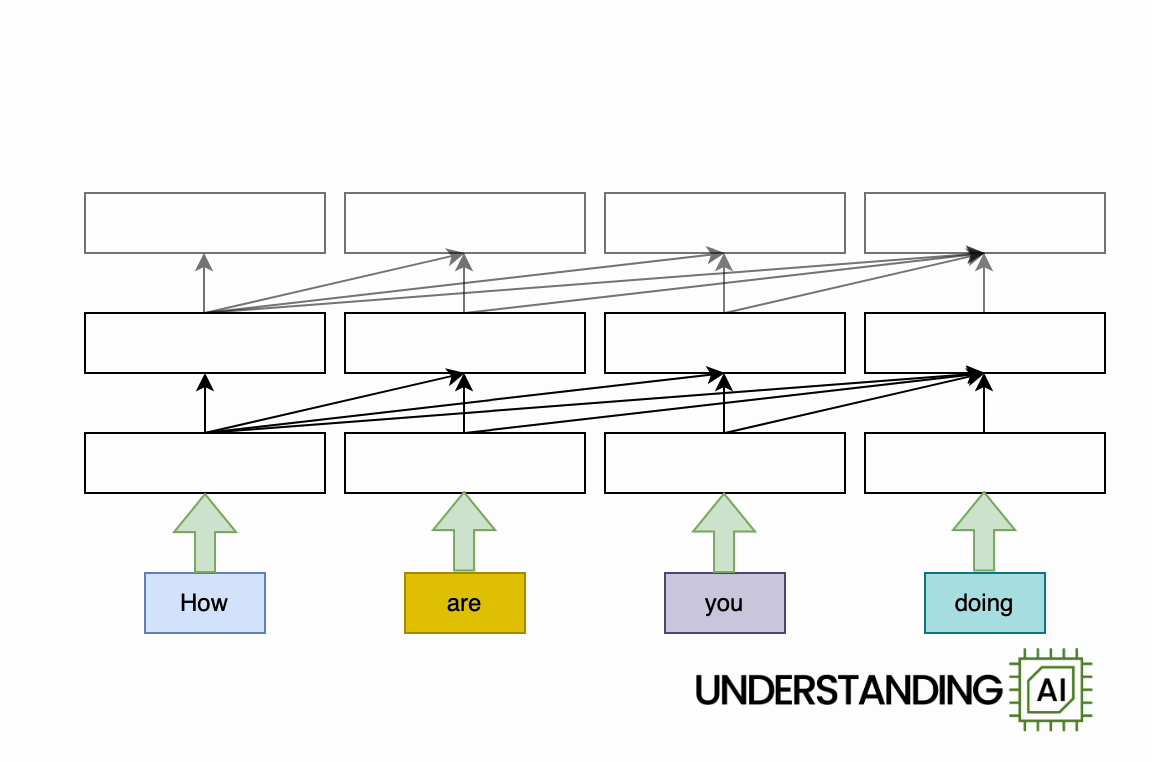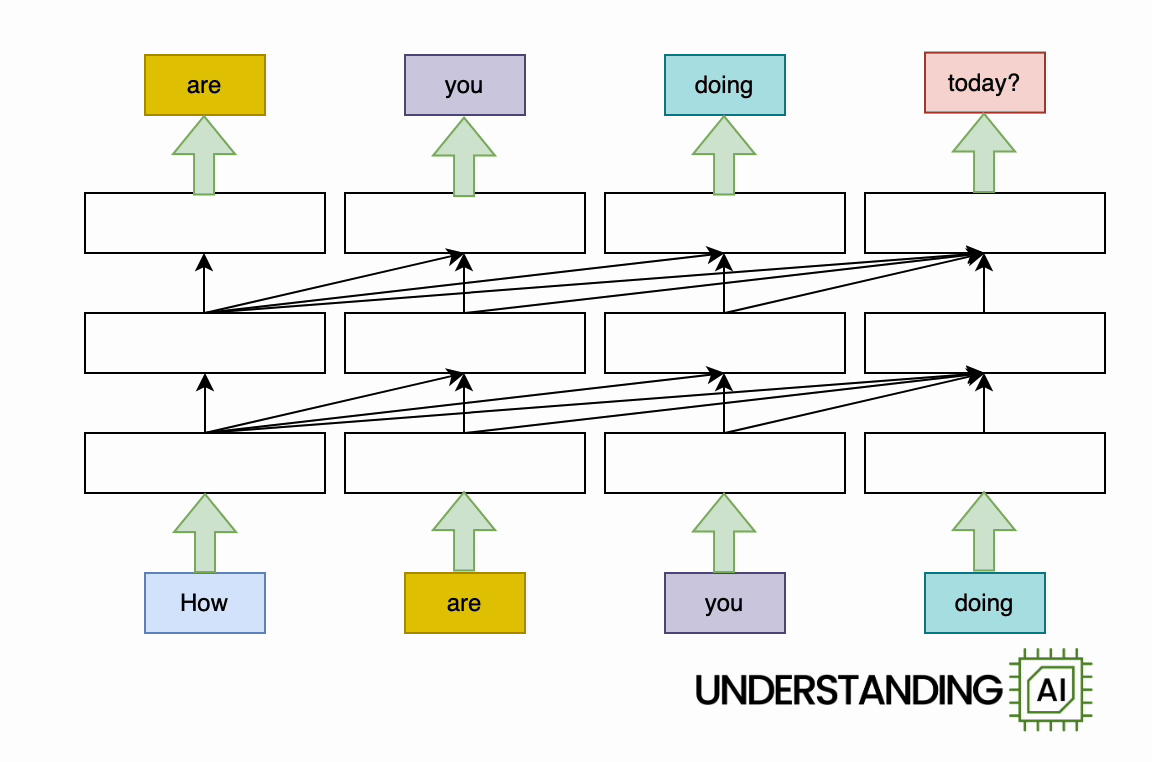
The transformer-based design revealed here does approximately as lots of calculations as the RNN in the previous diagram. It may not run any much faster on a( single-core) CPU. Due to the fact that the design does not require to end up with” How” before beginning on” are,”” you,” or” doing,” it can work on all of these words at the same time. It can run a[lotquicker on a GPU with lots of parallel execution systems.
Just how much quicker? The possible speed-up is proportional to the variety of input words. My animations portray a four-word input that makes the transformer design about 4 times faster than the RNN. Genuine LLMs can have inputs countless words long. With an adequately sturdy GPU, transformer-based designs can be orders of magnitude quicker than otherwise comparable RNNs.
Simply put, the transformer opened the complete processing power of GPUs and catalyzed fast boosts in the scale of language designs. Leading LLMs grew from numerous countless criteria in 2018 to numerous billions of specifications by 2020. Timeless RNN-based designs might not have actually grown that big due to the fact that their direct architecture avoided them from being trained effectively on a GPU.
See all those diagonal arrows in between the layers? They represent the operation of the attention system. Before a transformer-based language design produces a brand-new token, it “thinks of” every previous token to discover the ones that are most appropriate.
Each of these contrasts is low-cost, computationally speaking. For little contexts– 10, 100, and even 1,000 tokens– they are not a huge offer. The computational expense of attention grows non-stop with the number of preceding tokens. The longer the context gets, the more attention operations (and for that reason calculating power) are required to produce the next token.
This indicates that the overall computing power needed for attention grows quadratically with the overall variety of tokens. Expect a 10-token timely needs 414,720 attention operations. :
- Processing a 100-token timely will need 45.6 million attention operations.
- Processing a 1,000-token timely will need 4.6 billion attention operations.
- Processing a 10,000-token timely will need460 billionattention operations.
This is most likely why Google charges two times as much, per token, for Gemini 1.5 Pro once the context gets longer than 128,000 tokens. Getting token number 128,001 needs contrasts with all 128,000 previous tokens, making it substantially more costly than producing the very first or 10th or 100th token.
A great deal of effort has actually been taken into enhancing attention. One line of research study has actually attempted to squeeze optimal effectiveness out of private GPUs.
As we saw previously, a modern-day GPU consists of countless execution systems. Before a GPU can begin doing mathematics, it needs to move information from sluggish shared memory (called high-bandwidth memory) to much faster memory inside a specific execution system (called SRAM). Often GPUs invest more time moving information around than carrying out estimations.
In a series of documents, Princeton computer system researcher Tri Dao and numerous partners have actually established FlashAttention, which computes attention in such a way that decreases the variety of these sluggish memory operations. Work like Dao’s has actually drastically enhanced the efficiency of transformers on modern-day GPUs.
Another line of research study has actually concentrated on effectively scaling attention throughout numerous GPUs. One commonly pointed out paper explains ring attention, which divides input tokens into blocks and designates each block to a various GPU. It’s called ring attention due to the fact that GPUs are arranged into a conceptual ring, with each GPU passing information to its next-door neighbor.
I when participated in a ballroom dancing class where couples stood in a ring around the edge of the space. After each dance, females would remain where they were while guys would turn to the next lady. In time, every male got a possibility to dance with every female. Ring attention deals with the very same concept. The “females” are inquiry vectors (explaining what each token is “searching for”) and the “guys” are crucial vectors (explaining the attributes each token has). As the secret vectors turn through a series of GPUs, they get increased by every question vector in turn.
In other words, ring attention disperses attention computations throughout several GPUs, making it possible for LLMs to have bigger context windows. It does not make specific attention estimations any more affordable.
The fixed-size concealed state of an RNN indicates that it does not have the very same scaling issues as a transformer. An RNN needs about the exact same quantity of calculating power to produce its very first, hundredth and millionth token. That’s a huge benefit over attention-based designs.
RNNs have actually fallen out of favor given that the innovation of the transformer, individuals have actually continued attempting to establish RNNs ideal for training on contemporary GPUs.
In April, Google revealed a brand-new design called Infini-attention. It’s sort of a hybrid in between a transformer and an RNN. Infini-attention deals with current tokens like a typical transformer, remembering them and remembering them utilizing an attention system.
Infini-attention does not attempt to keep in mind every token in a design’s context. Rather, it shops older tokens in a “compressive memory” that works something like the covert state of an RNN. This information structure can completely keep and remember a couple of tokens, however as the variety of tokens grows, its recall ends up being lossier.
Artificial intelligence YouTuber Yannic Kilcher wasn’t too satisfied by Google’s technique.
“I’m extremely open up to thinking that this in fact does work and this is the method to choose unlimited attention, however I’m extremely doubtful,” Kilcher stated. “It utilizes this compressive memory method where you simply keep as you go along, you do not truly find out how to save, you simply save in a deterministic style, which likewise suggests you have extremely little control over what you keep and how you save it.”
Possibly the most noteworthy effort to reanimate RNNs is Mamba, an architecture that was revealed in a December 2023 paper. It was established by computer system researchers Dao (who likewise did the FlashAttention work I discussed earlier) and Albert Gu.
Mamba does not utilize attention. Like other RNNs, it has a covert state that functions as the design’s “memory.” Since the covert state has a set size, longer triggers do not increase Mamba’s per-token expense.
When I began composing this post in March, my objective was to describe Mamba’s architecture in some information. Then in May, the scientists launched Mamba-2, which substantially altered the architecture from the initial Mamba paper. I’ll be frank: I had a hard time to comprehend the initial Mamba and have actually not found out how Mamba-2 works.
The crucial thing to comprehend is that Mamba has the prospective to integrate transformer-like efficiency with the performance of standard RNNs.
In June, Dao and Gu co-authored a paper with Nvidia scientists that examined a Mamba design with 8 billion criteria. They discovered that designs like Mamba were competitive with comparably sized transformers in a variety of jobs, however they “drag Transformer designs when it pertains to in-context knowing and remembering details from the context.”
Transformers are proficient at details recall since they “keep in mind” every token of their context– this is likewise why they end up being less effective as the context grows. On the other hand, Mamba attempts to compress the context into a fixed-size state, which always indicates disposing of some details from long contexts.
The Nvidia group discovered they got the very best efficiency from a hybrid architecture that interleaved 24 Mamba layers with 4 attention layers. This worked much better than either a pure transformer design ora pure Mamba design.
A design requiressomeattention layers so it can keep in mind crucial information from early in its context. A couple of attention layers appear to be enough; the rest of the attention layers can be changed by less expensive Mamba layers with little effect on the design’s total efficiency.
In August, an Israeli start-up called AI21 revealed its Jamba 1.5 household of designs. The biggest variation had 398 billion criteria, making it similar in size to Meta’s Llama 405B design. Jamba 1.5 Large has 7 times more Mamba layers than attention layers. As an outcome, Jamba 1.5 Large needs far less memory than equivalent designs from Meta and others. AI21 approximates that Llama 3.1 70B requires 80GB of memory to keep track of 256,000 tokens of context. Jamba 1.5 Large only requirements 9GB, enabling the design to operate on much less effective hardware.
The Jamba 1.5 Large design gets an MMLU rating of 80, considerably listed below the Llama 3.1 70B’s rating of 86. By this step, Mamba does not blow transformers out of the water. This might not be an apples-to-apples contrast. Frontier laboratories like Meta have actually invested greatly in training information and post-training facilities to squeeze a couple of more portion points of efficiency out of criteria like MMLU. It’s possible that the exact same type of extreme optimization might close the space in between Jamba and frontier designs.
While the advantages of longer context windows is apparent, the finest technique to get there is not. In the short-term, AI business might continue utilizing creative effectiveness and scaling hacks (like FlashAttention and Ring Attention) to scale up vanilla LLMs. Longer term, we might see growing interest in Mamba and maybe other attention-free architectures. Or possibly somebody will create an absolutely brand-new architecture that renders transformers outdated.
I am quite positive that scaling up transformer-based frontier designs isn’t going to be a service on its own. If we desire designs that can manage billions of tokens– and many individuals do– we’re going to require to believe outside package.
Tim Lee was on personnel at Ars from 2017 to 2021. In 2015, he introduced a newsletter,Comprehending AI,that checks out how AI works and how it’s altering our world. You can subscribehere
Timothy is a senior press reporter covering tech policy and the future of transport. He resides in Washington DC.
36 Comments

Learn more
As an Amazon Associate I earn from qualifying purchases.





